提到栈,很多人会联想到之前讨论过的链表实现方式,但实际上两者存在显著差异。在Java中,栈的实现机制有其独特之处。本文将详细介绍Java中栈的具体实现原理与使用方法,涵盖基本操作和常见应用场景。通过阅读,你将掌握如何正确运用栈结构,理解其底层逻辑,并能在实际编程中灵活应用,从而提升代码效率与逻辑清晰度。
1、 许多人误以为栈继承自链表,实际上栈是继承自Vector类,因此其底层并非链式结构,而是基于数组实现的。这也说明栈在存储和操作上更依赖动态数组的特性,而非链表的节点连接方式。
2、 栈在底层虽基于数组实现,但其核心特性仍遵循先进后出原则。它直接继承自Vector类,未再扩展其他父类。正因如此,得益于Vector的同步机制,栈的操作具备线程安全性,可在多线程环境中安全使用其方法。
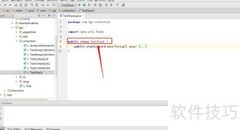
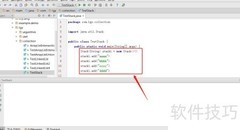
3、 栈在原有基础上结构简单,相比向量仅增加了入栈、查看和出栈操作。入栈与出栈操作较为常见,而查看功能则用于获取最顶层元素的值,但不会将其从栈中移除。
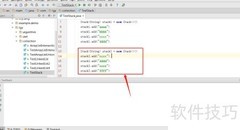
4、 由于继承了vector类的全部方法,stack堆栈实际上支持直接插入、删除和随机访问元素,这与我们通常对堆栈后进先出特性的理解存在较大差异。表面上看是一个堆栈,但在代码中却能随意操作任意位置的元素,相当于具备了超出堆栈本身所需的功能,实际上实现了一些本不应具备的操作能力。
5、 由于这一缺陷,目前多数堆栈的实现倾向于采用链表的变体,而非直接使用传统栈结构。尽管如此,接下来我们不妨来看几个栈的实际应用示例,以加深理解其在具体场景中的运用方式。
6、 栈的基本功能大致如此,其设计初衷是为了解决堆栈操作的需求。然而,个人认为直接继承自vector是一种失误,虽图一时便利,却违背了栈的封装原则。它所提供的add、set、get等方法完全突破了栈后进先出的限制,破坏了数据结构的严谨性,最终导致其在实际应用中逐渐被弃用,走向边缘化。




























评论
更多评论