近期收到许多关于Python数据挖掘的疑问,现整理出具体操作步骤,涵盖数据预处理、模型构建与分析等关键环节,希望能为有需要的人提供实用参考和帮助。
1、 数据分析模块中,numpy因其高效的数据处理和数组支持而成为核心基础。众多常用库如pandas、scipy和matplotlib均依赖于它,因此在搭建数据分析环境时,必须优先安装numpy,以确保其他模块能够正常运行,它是整个数据科学工具链的基石。
2、 pandas 主要用于数据的采集与分析,能够高效处理结构化数据,支持灵活的数据清洗与操作。scipy 专注于科学计算,提供丰富的数值运算功能,支持矩阵运算,并涵盖积分、微分方程求解等高级数学工具。matplotlib 是一个强大的绘图库,可将数据分析结果以图形形式直观展示,实现数据可视化。statsmodels 模块侧重于统计建模与分析,适用于回归分析、时间序列等统计任务。Gensim 专注于文本挖掘领域,擅长主题建模与文档相似度计算。sklearn 提供全面的机器学习算法,支持分类、聚类、回归等任务,而 keras 是一个深度学习框架,简化了神经网络的构建与训练过程,便于快速实现复杂模型。
3、 安装时务必选择带MKL支持的NumPy版本。该版本在执行操作时不返回新值,而是直接修改原始数据。例如x.max()可获取二维数组的最大值,x.min()获取最小值,这些方法对多维数组同样有效。通过x1 = x可实现数组引用而非复制,切片操作方式与Python列表一致,适用于区间选取。
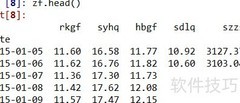
4、 通过pandas可以便捷地导入各类数据,该库支持多种常见文件格式。日常使用中,最频繁接触的包括CSV、Excel等格式,更多类型可参考官方文档或源码说明。以CSV文件为例,导入后默认按原始行列结构展示,列数与文件实际一致。例如,若数据包含五列,输出时便会完整呈现这五列内容,保持原有布局不变,便于直观查看和后续处理。
5、 接下来是读取SQL数据,该过程依赖于PyMySQL库,因此需提前安装该模块。当使用pandas读取SQL时,必须提供两个参数:其一是具体的SQL查询语句,其二是已建立的数据库连接实例。在读取HTML内容时,需要借助lxml库的支持,请确保已安装。若涉及HTTPS协议的网页,则还需安装BeautifulSoup4和html5lib两个辅助模块。需要注意的是,HTML读取功能仅提取网页中的表格数据,即仅解析由标签包围的内容。对于txt文本文件的读取,系统在输出结果时会自动添加行号与列名标识,便于数据查看与分析。
6、 安装方法上,可直接使用pip install命令来安装matplotlib数据可视化分析模块,无需预先下载whl格式文件。相比先下载whl再通过pip安装的方式,此方法更为简便快捷,系统会自动处理依赖和版本匹配,推荐优先采用直接安装方式完成模块的配置与部署,提高效率并减少操作步骤。





































评论
更多评论