
11月27日,新加坡国家人工智能计划推出了一款名为Qwen-SEA-LION-v4的多语言大模型,专为服务东南亚地区设计。该模型以阿里巴巴开源的“通义千问”技术为基础进行研发,聚焦应对区域内复杂的语言使用环境。
东南亚是全球语言多样性最丰富的区域之一,拥有超过1200种语言,日常交流中普遍存在多种语言交织混用的现象。然而,当前主流人工智能模型多以英语为核心,对本地语言支持有限,导致技术应用与实际需求之间存在明显落差。此次发布的模型正是为了弥合这一“AI鸿沟”,推动本地化人工智能发展。
据官方资料显示,Qwen-SEA-LION-v4已在“东南亚语言模型全面评估基准”(SEA-HELM)的开源模型榜单中取得领先成绩,位列参数量低于2000亿类别的首位。其卓越表现得益于底层架构在多语言处理能力上的深度优化。
该模型依托Qwen3系列在预训练阶段即覆盖119种语言的优势,具备较强的东南亚小语种理解能力。研发过程中,技术团队进一步强化了跨语言训练任务的比重,使模型能够更高效地识别和响应真实场景中的混合语言输入。
目前,Qwen-SEA-LION-v4已通过AISingapore官网及HuggingFace平台向全球开放,供公众免费下载使用,助力更多研究机构与开发者参与本地化AI生态建设。
















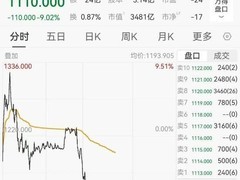


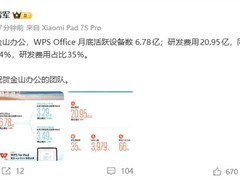




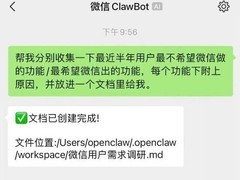























评论
更多评论