
苹果M4与英特尔酷睿Ultra7 的“轻薄本之争”
大家现在买笔记本的时候,是不是特别纠结?
一边是苹果最新的M4,续航长、系统流畅、运行安静,几乎不发热、不卡顿,剪视频、写稿、做设计样样都稳,是不少内容创作者和职场用户心里的“安全区”;哪怕你不搞创作,MacOS 那种“拿来就能用、用起来不出错”的稳定感,也确实有吸引力。
但话说回来,也不是所有人都会喜欢Mac。它的系统封闭,很多软件不好装;配置不可升级,预算一上来就很难控制;生态相对统一,这也意味着给消费者的选择更少。
而今年英特尔推出的酷睿Ultra7 258V,则让Windows阵营也开始变得有意思起来,甚至有追平AppleM系芯片的能力:大幅降低功耗,续航大幅提升,还加入了专用的AI运算芯片(NPU),可以本地运行越来越多AI工具和生成式应用;再加上我们熟悉的Windows系统以及更强的扩展性、丰富的产品选择和更灵活的价格区间,对不少用户来说,反而更自由、更实用。
那么问题来了,如果一个普通消费者,不是开发者,也不是靠剪视频做设计吃饭的专业人士——你只是希望有一台能轻松搞定日常办公、续航强大、还能部署专属AI的笔记本,那到底应该怎么选?是继续相信Mac的稳定、安静和高续航,还是尝试一台更开放、可拓展、能跑本地AI、价格上更有优势的Windows笔记本?
这篇文章,我们选择了Windows和MAC阵营的两台笔记本电脑,从芯片架构、AI性能、实际使用体验,到生态和成本,一一说清楚。
同价位“顶配轻薄本”,区别在哪?
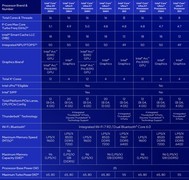
我们先来看看这次对比的两台机器,分别是联想的ThinkPad X9-14 Aura AI 和苹果的MacBook Air 13(M4版)。别看一个是Windows阵营、一个是macOS阵营,它俩的定价其实非常接近——都是1.3万元上下,甚至都标配了32GB内存和1TB大容量存储,算是各自体系下非常“顶配”的轻薄本了。
联想ThinkPad X9-14 Aura AI 搭载的是英特尔今年主推的酷睿Ultra7 258V,这是基于全新LunarLake 架构打造的处理器,采用了台积电N3B工艺,内部是4个高性能P核+4 个高能效E核的混合设计。
这代处理器最大特点就是功耗压得非常低,同时首次内置了47 TOPS 的NPU,专门用于本地AI运算。此外,它还集成了新一代Arc140V 核显,采用Xe²架构,图形性能相比上一代大幅增强,甚至能跑一些3A游戏。整体来看,这颗CPU是英特尔专门为轻薄AIPC 打造的,主打低功耗、高能效和AI应用支持。
而苹果这边的MacBookAir 则采用了最新的AppleM4 芯片,继续延续自研Arm架构,配备4个性能核心和6个能效核心的10核CPU,搭配统一内存架构、10核GPU和16核NPU。
整体设计还是以轻量、能效为核心,适合日常使用和内容创作等主流场景。
虽然M4芯片在硬件上具备不俗的AI运算能力,但苹果目前推出的AppleIntelligence 功能尚未对国内用户开放,相关功能处于早期测试阶段,暂时还无法真正落地。因此对于大多数用户来说,这部分AI能力短期内难以体验到,整体体验更多还是停留在macOS本身的系统优化与生态优势上。
参数看起来都不差,但实际体验才是关键。尤其在这个AI时代,CPU的性能、调度效率和本地算力能力,比以往更重要。
接下来我们来看看这两颗芯片在真实使用下,表现到底如何?
图形与AI性能实测
在图形性能方面,我们先分别对两台设备的核显(iGPU)进行了3DMark测试,包含SteelNomad Lite DX12、Vulkan,以及WildLife Extreme 三个项目。
首先是SteelNomad Lite DX12,这个测试只支持Windows平台,因此只有英特尔酷睿Ultra7 258V 能跑,得分为3095分。
苹果M4因为不支持DX12,无法参与这项测试,但这也正体现了两个平台在图形API支持上的一个明显差异——Windows本地对DirectX的支持依然是它的强项,尤其对玩游戏、跑传统图形渲染的用户来说更友好。
在SteelNomad Lite 测试中,我们选择Vulkan作为统一的渲染API,以确保两台设备都能参与对比。结果显示,苹果M4的得分为3834分,而搭载Arc140V 的英特尔酷睿Ultra7 则为3034分。
虽然从分数上来看苹果领先,但英特尔这边的表现其实更值得关注:作为一颗集成核显,Arc140V 在Vulkan这种跨平台高负载场景下依旧稳定跑进3000分区间,体现出不俗的图形调度能力和生态兼容性。
这也意味着,对于很多日常使用Vulkan开发环境的AI工程师、图形设计师或多平台开发者而言,酷睿Ultra平台不仅能提供足够的图形算力,更在工具支持和跨平台调试中具备明显优势。
最后我们来看一项更偏向移动端真实游戏场景的测试—— WildLife Extreme。这项测试模拟的是高负载游戏画面下的持续图形渲染能力,最终结果显示:苹果M4拿到了8706分,而英特尔酷睿Ultra7 258V 的Arc140V 核显则得到了6957分。
从分数上看,M4确实有更强的稳定性和能效调度优势。但英特尔平台的得分也不低,在轻薄本集显中依旧处于中上游水准,而且它运行的是原生Windows游戏环境,支持更广泛的API和图形驱动。
更重要的是,Arc140V 拥有良好的DX支持与可扩展性,在《英雄联盟》《CS2》这类主流网游中,稳定跑出比较稳定的帧数,如果你需要更强图形性能,甚至还可以接驳外接显卡坞进一步拓展。
接下来我们来看看它们的Ai性能表现,英特尔是在2023年下半年正式提出“AIPC”概念的,从那之后,不论是芯片中集成NPU、还是软硬件配合优化,它几乎把AI当作下一阶段PC的核心能力在推进。苹果这边虽然说得少,但早在2017年发布A11芯片时,就已经在iPhone上加入了专用的神经网络引擎(NPU),之后每一代芯片也都在默默增强AI计算能力。
两家厂商虽然路径不同,但目标一致——都想让设备更懂用户、更能本地处理智能任务。英特尔有自己的OpenVINO框架,主要服务于Windows端AI推理、图像识别等场景;而苹果则用CoreML将AI融入macOS和iOS系统中,用起来更像“系统功能”的一部分。
为了更直观地对比两台机器的AI理论性能,我们用Geekbench6 AI 和ULProcyon 的AIComputer Vision 测试进行跑分,分别调用了每个平台原生的AI框架。这类测试虽然不能完全代表实际体验,但足以看出两款芯片在AI运算上的设计取向和性能释放情况。
在AI和图形测试中,苹果M4的理论性能看上去确实不差。比如在GeekbenchAI 测试中,M4的NPU项拿到了较高分数,部分跑分上领先于英特尔酷睿Ultra7 258V。
但问题是:这些性能,目前普通用户几乎用不上。AppleIntelligence 尚未在国内开放,M4上的NPU基本没有实际用途。再强的算力,没有生态支持和软件落地,终究是“堆料”。
反观英特尔Ultra7 258V,它的GPU、CPU在多精度AI运算上表现更为均衡,尤其在GPU的量化、半精度和单精度运算上全面领先,能轻松胜任图像生成、字幕识别、视频增强等高强度本地AI任务。而这一切,不需要等待系统更新,也不依赖服务区开通。
在ULProcyon 的AIComputer Vision 测试中,英特尔凭借Xe2核显的XMX矩阵引擎,直接在FP16和INT8等实用项中实现反超,表现更接近现实AI应用的负载场景。比如运行本地大模型、部署自动配图、做局部换脸、视频AI上字幕,这些都已经能在英特尔平台稳定落地。而M4,即使理论分高,目前也没法做这些事。
实际AI体验:
当然,跑分只是检验性能门槛的敲门砖,真正能不能落地、能不能跑得顺才是关键。
我们测试了两个当前使用最广泛的本地大模型平台:LMStudio 和Ollama。这两个软件都支持一键加载模型并提供直观的交互界面,适合普通用户快速上手。其中,LMStudio 原生支持Windows和macOS,分别调用Vulkan和Metal图形接口;而Ollama除了官网提供的通用版本外,英特尔还专门推出了一个为酷睿处理器深度优化的版本,能进一步发挥其CPU与Xe核显的联合推理性能。
我们统一选择了同一组蒸馏后的DeepSeekR1 14B 模型,用一个典型的二元方程组作为推理样本进行推理速度测试与推理质量验证。
从LMStudio 的测试结果来看,ThinkPadX9-14 Aura AI搭载的酷睿Ultra7 258V 表现非常稳定,Token/s达到9.2,领先M4的7.25;
虽然首个Token的响应时间略慢,但整体生成速度更快,推理体验更流畅。
而在Ollama环节,由于英特尔优化版Ollama的加持,X9AURA 的性能几乎与M4持平甚至略有反超:Token/s达到9.7,高于M4的9.25。
在模型加载时间上,X9AURA 也更胜一筹,仅用时21秒即完成模型初始化,比M4的24秒更快完成准备阶段。虽然在提示词响应阶段M4的速度略快,但英特尔的表现已非常接近,且整体体验区别不大。
除了我们刚才测试的Ollama、LMStudio 这些AI模型平台,其实现在很多厂商也已经在轻薄本中预装了本地AI助手,比如Windows自带的Copilot+,或像联想这台X9-14Aura AI自带的联想天禧AI助手。
它主打的是一套可本地运行的轻量AI工具,比如智能问答、摘要生成、PPT制作建议、邮件润色、文生图等,界面简洁、响应迅速,日常办公场景中非常实用。
更重要的是,天禧很多功能并不依赖联网,可以基于本地部署的7B大模型调用设备的NPU和CPU本地完成推理响应,响应快、功耗低,对数据安全也更友好。像我们在实际使用中测试的文档总结、会议记录转写这些功能,体验都比较顺滑,能有效提升日常效率。
可以说,对于不想自己折腾模型、也不熟悉AI平台的用户来说,像天禧这种“开箱即用”的AI助手,是AIPC 真正落地的第一步。
实际应用体验:
除了大模型推理、图像生成这类“重负载”任务,AIPC在日常办公里的实际价值同样不容忽视,特别是在视频会议场景下。比如腾讯会议这类主流工具中常用的「背景虚化」「美颜」等特效,现在已经全面支持调用NPU进行加速处理。
在实际测试中,我们分别使用ThinkPadX9-14 Aura AI 和MacBookAir M4 开启“模糊背景”效果,并观察功耗与硬件资源分布。
在搭载英特尔酷睿Ultra7 258V 处理器的ThinkPadX9-14 Aura AI 上,AIBoost NPU 成功被调度,CPUIA 核心功耗稳定在约1.46W,Arc核显处于低负载状态,系统整体仍保持在低功耗运行区间。得益于专属NPU的分担,这一过程无需过度依赖CPU/GPU,能效表现非常理想。
而在MacBookAir M4 上,系统同样调用了AppleSilicon 的NPU模块,CPU+ GPU + NPU 的合计功耗大约在1.28W左右,控制得同样优秀。两款设备都能顺利完成背景模糊计算,区别在于调用逻辑与调度策略不同。
不过,英特尔这边的好处是平台开放度高、第三方适配成熟度高,比如OBS、腾讯会议等软件几乎都能第一时间获得优化支持。同时X9-14Aura AI 也有更强的接口拓展能力、更高的显示输出上限,对于需要外接多个屏幕或频繁远程办公的用户来说更加实用。
除了会议场景,在剪辑软件中使用AI功能也逐渐成为生产力的一部分。我们这次选用了支持AI抠像的万兴喵影,在两台机器上进行实测,看看谁能更快、更稳地扛住这类本地AI运算。
测试场景相同:导入4K视频素材,应用AI抠像特效,并进行实时预览与拖动播放。
在搭载英特尔酷睿Ultra7 258V 的ThinkPadX9-14 Aura AI 上,系统调度非常积极,AIBoost NPU 有效介入,CPU多核心频率跑满,IA核心功耗达到16.65W,整体CPUPackage 为24.42W,GPU也维持在24%左右负载。在这样高强度的负载下,预览画面依旧顺滑,响应非常迅速,几乎无感知延迟。可以看出英特尔这代平台在高并发调度、多模块协作方面优化非常到位。
反观搭载AppleM4 的MacBookAir,虽然也顺利完成了同样的操作,但更偏向于依赖CPU+GPU协同完成主运算,ANE模块并未参与,整体功耗被控制在7.4W左右。在实际体验中,虽然剪辑画面大体流畅,但在特效加载、时间线跳转等操作中,会出现轻微的延迟或停顿,说明在高算力AI场景下仍有一定压力。
综合来看,X9-14Aura AI 的优势不仅体现在处理速度更快,更关键的是它展现出强大的调度能力与平台优化,在实际剪辑工作中能明显减少等待时间。而M4虽然能效比出色,但在面对重度AI视频任务时,依旧更适合作为轻负载办公工具。
续航:
对于一台日常随身用的轻薄本来说,续航到底强不强,其实不只是看电池多大,而是看它在各种不同场景下“吃电”的效率。尤其是像AppleM4 和英特尔酷睿Ultra7 258V 这种主打AI能力的轻薄平台,如果性能强但续航拉胯,也会直接影响我们在外办公、追剧、开会的体验。所以我们这次专门做了三组Procyon场景测试,分别对应日常办公、视频播放和空闲待机,看看它们到底谁更耐用、谁更聪明地用电。
在Office测试中,酷睿Ultra7 258V 的功耗为3.45W,虽然略高于AppleM4 的3.3W,但差距非常小,属于同一水平。值得注意的是,在实际操作体验中,英特尔平台凭借更激进的线程调度策略,在多窗口文档、表格、网页切换中能提供更快的响应反馈,因此略高的功耗换来的,是更具效率的使用体验。
视频播放场景中,酷睿Ultra的功耗为3.85W,对比M4的3.675W依旧只高出约0.2W,差异极小。从播放流畅度与帧率稳定性来看,两者体验基本一致,但在部分高码率片源播放中,酷睿Ultra依托更强的iGPU与编解码硬件,解码负载更稳定、画面切换更顺畅。
真正拉开差距的是Idle空闲待机表现。酷睿Ultra7 258V 实测功耗低至1.65W,几乎是M4的一半(3.156W)。这说明在合盖、锁屏、后台挂载等场景下,X9-14Aura AI 能以更高效的能耗控制机制拉长整机待机时间。这对于需要长时间移动办公、频繁唤醒的用户而言,是一项非常实用的优化。
总结来看,虽然两款平台在主动使用场景中的功耗差距非常小,但酷睿Ultra在空闲控制方面展现出明显优势,这种“用则尽力跑、不用则极致省”的策略,为高频移动办公用户提供了更加灵活与耐用的续航保障。
总结:
如果我们把这场对比看作一场综合能力考试,那其实现在已经可以交卷了。因为不止性能单项出彩,联想ThinkPadX9-14 Aura AI 这台机器在整机体验上,也远比你以为的更强大、更全面。
从外观和做工来看,ThinkPadX9 Aura AI 属于典型的“沉稳派”选手,摸上去是ThinkPad一贯的硬朗质感,机身仅1.27kg,厚度控制得不错。
这块屏幕14英寸、2.8K分辨率的OLED触控屏,不但支持120Hz高刷新率,还覆盖100%DCI-P3 色域、亮度达到了500nit,连专业用户都挑不出毛病。MacBookAir M4 的屏幕固然也优秀,但它不是触屏,也不是OLED,所以如果你对画面层次、触控交互、甚至创作绘图类场景有需求,那X9是实打实的一步到位。
当然,最核心的还是性能表现。我们前面已经跑了非常多测试,从AI本地部署、到视频会议背景虚化、再到AI抠像处理,英特尔酷睿Ultra7 258V 在X9上的综合表现非常亮眼。
回到文章一开始我们提出的问题:苹果M4还是酷睿Ultra7?
经过这段时间对ThinkPadX9-14 Aura AI 和MacBookAir M4 的深度体验,我的结论是:差距,正在迅速缩小。
先说性能。过去我们总觉得ARM架构天生能效高、温控稳,x86总是“高性能但发热大”。可现在,英特尔这颗酷睿Ultra7258V,已经彻底扭转了这种印象——本地跑大模型、处理图像、剪辑视频这些重活,它不光扛得住,还扛得非常从容。而且不需要牺牲太多功耗或风扇噪音来换性能,日常工作甚至AI操作都能维持非常稳的能效表现。
尤其在AI这块,英特尔是真的动真格了。除了硬件层面的NPU+ Xe 图形引擎,英特尔还投入了大量资源在本地AI应用和生态适配上。你看我们实测用的Ollama、LMStudio、AI抠像、虚拟会议背景模糊,这些原本对硬件要求不低的功能,现在在X9上都能跑得有模有样,很多软件甚至优先适配英特尔平台版本,体验比在M4上更完整。
续航方面苹果还是略占上风,这是它架构带来的天然优势。但酷睿Ultra7 258V的功耗已经拉得非常接近了,Idle状态下差不多腰斩,一整天的外出办公基本都能撑住。
另外不得不提一点:生态和扩展性。如果你和我一样,是需要用到HDMI、多个USB接口、移动硬盘、专业外设的重度办公用户,那X9的配置和接口真的香。再配上Windows全平台的兼容性、本地AI工具的灵活性,还有企业级的售后服务,整体体验是更贴近国内用户需求的。
这代酷睿Ultra200V 系列,正在用一个非常稳的姿态,把曾经属于ARM的能效优势一步步夺回来。而在我们最关心的本地AI能力、办公效率、生态扩展这些商用核心场景里,它甚至已经走在了前头。




















































































































评论
更多评论