
1月26日,Hugging Face发布了两款全新多模态模型:SmolVLM-256M和SmolVLM-500M。据悉,这两款模型都是基于去年训练的80B参数模型进行提炼而成,实现了性能与资源需求之间的平衡。官方表示,这两款模型可以直接部署在transformer MLX和ONNX平台上。
具体来说,SmolVLM-256M采用了SigLIP作为图片编码器,而SmolVLM-500M则使用了更强大的SmolLM2作为文本编码器。值得一提的是,SmolVLM-256M是目前最小的多模态模型之一,它可以接受任意序列图片和文本输入,并生成文字输出。该功能包括描述图片内容、为短视频生成字幕以及处理PDF等任务。
关于价格方面,在移动平台上运行仅需不到1GB的GPU显存即可完成单张图片的推理工作。而对于需要更高性能的企业运营环境来说,则更适合使用 SmolVLM-500M ,该模型在单张图片上仅需1.23GB的GPU显存,虽然负载较大,但其输出结果更加精准。
最后要注意的是,这两款模型都采用了Apache 2.0开源授权,并提供了基于transformer和WebGUI的示例程序。所有模型及其演示已公开便于开发者下载和使用。











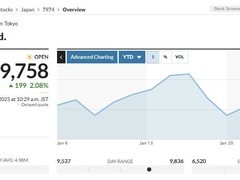











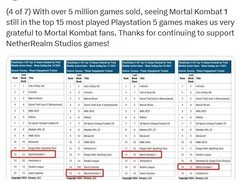








































评论
更多评论