【中关村在线】蓝宝石FireProW9100评测: 将GPU应用于通用计算的概念从提出至今已经有大约15年的时间,在此期间,GPU 的发展日新月异,从固定功能单元为主发展到现在已经出现了绝大部分渲染功能都可以由内部大规模的通用计算单元实现。
以蓝宝石PGS AMD FirePro W9100为例,它集成了2816 个 PE(处理单元),每秒能执行 5.2TFLOPS单精度计算或者2.6TFLOPS双精度计算,具备320 GiB/s的内存带宽以及高达16GiB的内存容量,性能/耗电比率远超CPU。
在近两年的全球超级计算机 500 强中,基于 GPU 或者说以 GPU 作为主力加速器的大型机已经成为最重要的推动力量,前十名中一直有多台都是 GPU 超算系统,这说明了一个很简单的现实:GPU 加速已经获得了市场认可。 不过一个产品要获得市场认可的话,从技术层面而言,一定需要提供些数据才有说服力。
在 08年就正式介入 GPU 通用计算的美国 Oak Ridge National Laboratory(橡树岭国家实验室)于 2010 年公布了一个名为 SHOC(Scalable HeterOgeneous Computing)的性能测试包,尝试从真正的超算用户角度找到一个判断各规模下的异构系统性能的解决方案。
顾名思义,SHOC 是一个针对异构系统性能的可延伸性测试工具,支持 OpenCL 和 CUDA,它包含了性能测试和稳定性测试,其中性能测试按照测试的复杂性划为三个 level 或者说三组测试项目:
Level 0用于测试设备的特征(吞吐率、速度),例如 GPU 总线带宽、设备的峰值浮点性能等。
总线速度(Download 与 Readback),Download 和 Readback 分别表示 GPU 从主内存读取数据以及将数据从加速卡的内存读取回主内存。
设备内存带宽:对加速卡所有类型内存的带宽进行测试。包括全局内存、本地内存、常数内存、图像内存,这些内存的概念都是源自 OpenCL 中的定义。其中全局内存地址空间采用了 coalesced 和 uncoalesced 两种存取方式进行测试。这些测试所采用的存取线程粒度是 16 个独立内存存取请求。
内核编译时间。
峰值浮点性能(单精度和双精度)。
队列化延时。测量一个 kernel 从递交到队列到开始在“设备”上执行之间所需要的平均时间开销。
Level 1 用于基本算法性能,例如 FFT、向量点积和筛选操作。
广度优先搜索(BFS):BFS 是一种对树进行完全遍历的搜索算法,在 SHOC 中的 BFS 测试采用了两种实现,分别来自斯坦福大学和伊利诺伊大学香槟分校(UIUC),SHOC 对这些算法进行了一些修改,使其可以适用满足正确性和多平台兼容性。测试的精度没有特别要求,“图(或者说关系树)”数据是无符号整型。
快速傅里叶转换(FFT):测量单精度和双精度快速傅里叶转换的性能。
分子动力学(Molecular Dynamics,MD):测量进行分子动力学中的兰纳-琼斯势性能,该测试采用了在像 LAMMPS 应用中成品级 MD 代码所使用的 neighbor-list 算法。数据类型有单精度和双精度。
归约(Reduction):用于测量大规模浮点加运算规约的性能。
并行前缀求和(Scan):测量对大规模浮点矩阵执行并行前缀求和的性能。
广义矩阵乘法(GEMM):测量 GEMM BLAS 性能,单精度。
排序(Sort):测量无符号数矩阵基数排序性能。
稀疏矩阵向量乘(SPMV):测量多种算法和数据结构下的稀疏矩阵向量乘法性能。
Stencil2d:测量对一个二维的 9 点单精度 stencil 执行计算的性能(包括 PCIe 传输)。
Triad:就是 Stream 中 Triad 的 OpenCL 版本,所谓的 Triad 就是把 copy、Scale、Add 三种操作组合起来进行测试,采用单精度执行计算。
Level 2,测试真实应用中采用的内核性能:
S3D:在一个标准三维栅格上测量遄流燃烧求解器计算的性能,这是一个浮点计算密集型的应用测试,栅格中每个栅格点的计算需要执行 10000 次浮点操作,这些栅格点都对应到 OpenCL 设备中一个的 work-item。
SHOC最早是在 ORNL 的官网以开源代码方式提供,后来转移到了开源平台git上,目前提供了Linux和Windows版本,不过只有Linux是支持OpenCL的,因此要使用SHOC测试OpenCL设备的话,就必须在Linux下进行。
我们这次选择了 CentOS 7.0 x86_64 作为操作系统,安装的时候选择开发人员方案并且选上了一些必要的开发组件。需要注意的是,目前的一些 Linux 发行版默认安装的时候对 Intel 的企业 SSD 支持并不好(安装的时候找不到 SSD),例如 CentOS 和 Ubuntu 都存在这个问题,所以我们这次简单一点,只是在机械硬盘上安装的,这对测试结果不会造成影响。安装的时候选择英文界面,这样有利于在命令行敲指令。
完成CentOS 安装后,就到程序里选择软件更新,更新完以后重启电脑。我们这次测试的都是AMD FirePro专业卡,因此需要到AMD官网或者蓝宝石PGS官网下载Linux x86_64驱动。
AMD 官方 Linux 驱动安装是完全视窗化的,只要以管理员权限执行解压后的 fgl-xxx(你不需要完整敲出每个字母,只要敲对文件的前几个字母,然后按 tab 键就能自动补全),就会弹出一个驱动安装界面,依照提示执行即可,然后重启。
安装完驱动后,就得安装 APP SDK Linux 版,下载地址同上,也是以管理员权限执行解压后的文件即可,我们这次安装的 SDK 版本号是 2.9.1,完全安装后,重启。完成驱动和SDK安装后 到终端里执行 clinfo 指令,此时应该会显示出当前系统的 OpenCL 设备特征和属性列表。
接下来就是下载、配置和编译 SHOC 了。SHOC的下载链接:https://github.com/vetter/shoc,点击右侧的,点击右侧的 Download zip,就会出现下载窗口提示框。
解压下载的文件,然后在终端中进入该目录,新建一个 shoc-build 目录(mkdir shoc-build),再进入该目录,执行以下命令进行配置(安装 SDK 的时候选择了默认路径,所以这里的 include 和 link 路径都指定到 SDK 的默认安装路径:opt/AMDAPPSDK-2.9-1):sh ../configure CPPFLAGS="-I/opt/AMDAPPSDK-2.9-1/include" LDFLAGS="-L/opt/AMDAPPSDK-2.9-1/lib/x86_64" --with-opencl 执行完配置后,就敲 make 命令进行编译构建,构建完毕后,再进入构建时候生成的 tools 目录中,执行以下指令就能运行 shoc 测试了:sh ./shocdriver -p 0 -d 0 opencl。
需要注意的是,上面这个例子没有指定求解规模(problem size),默认的求解规模是匹配 CPU 这类 opencl device 的,无法充分利用 GPU 的资源,所以你会看到测试出来的部分结果是偏低的,对于这个级别的求解规模来说是正常的现象。要指定求解规模的话,可以在执行执行的时候,加上一个-s参数,例如 -s 4,就是指定求解规模匹配具备大内存的 FirePro。
因此,在高配置的超算卡上执行 SHOC 的单节点完整指令是:sh ./shocdriver -p 0 -d 0 -s 4 opencl如果配置了 MPI 并且采用了 MPI 来构建 SHOC 的话,你还可以使用 -n 来指定运行多个节点,然后用 -d 来指定各个节点上运行哪几个 device。
例如: sh ./shocdriver -n 4 -d 0,1 -s 4 opencl 就是表示同时跑 4 个节点,并且各个节点里运行的 device 编号是 0 和 1。影响性能测试结果的因素其实不仅于此,例如直接和 displayport 显示器连接的话性能是有可能比透过转接更快,这其中的原因可能是因为驱动或者技术上的缘故。
测试平台:
CPU:Intel Xeon E5-1620
主板:华擎工作站主板 EPC602D8A
内存:DDR3-1600 8GiB*2,双通道配置
操作系统:CentOS 7.0(已更新)
编译器:GCC 4.8.2
测试结果
Level 0 测试结果
Level 0测试的是诸如内存带宽、总线带宽、计算性能这类底层的性能,也都是厂商在宣传上直接可以给客户看到的指标。众所周知的是,这类指标的参考价值并不能反映实际的性能,有时候底层性能一样的两代显卡,在实际应用中的性能往往截然不同。
但是不管怎样,这个指标便于初步在同一代产品中作遴选以及快速判断系统是否已经就绪,所以 SHOC 还是将其纳入到测试中,将这类测试定义为 Level0 组别。蓝宝 PGS AMD FirePro W9100 具备 2:1 的单双精度设计,单卡就能提供 5.2TFLOSP 单精度或者 2.6TFLOPS 双精度性能,16GiB 内存能提供高达 320 GiB/s 的带宽,从超算的角度而言这些指标都是目前业界最先进的水平。达成这些指标的根本原因在于蓝宝 PGS AMD FirePro 集成了 2812 个计算单元和高达 384-bit 的内存总线,计算性能和带宽目前是没有对手可言的。
level 0 测试包括了以下内容:
BusSpeedDownload:OpenCL 设备从系统主内存读取数据,这里一般是用于测试 PCIE 通道的读取性能。BusReadBack:将 OpenCL 设备上的数据写回到系统主内存,这里一般是用于测试 PCIE 通道的写回性能。
对GPU 这类 OpenCL 设备来说,这组测试本质上其实就是测试 PCIE 带宽。相对于 Wx000 系列而言,Wx100 系列在 host->device 的 download 测试中差别不大,不过在 device->host 的 readback 中则有大约 7% 的提升。MaxFlops:最高单精度和双精度浮点性能。
maxFlops 的测试结果就是让 device 跑一大堆 madd 指令的 work-item 然后除以运行时间。这里的测试结果有单精度和双精度两个项目,从测试结果来看,非常接近于各显卡的理论性能,例如 FirePro W9100 的单精度/双精度性能分别是 5.2 TFLOPS 和 2.6 TFLOPS,这里测试出来的结果是 5.0 TFLOPS 和 2.5 TFLOPS。gmem_readbw:全局内存读取带宽。
gmem在这里是指OpenCL 中的 Golbal Memory 这个存储级别对应的内存,在显卡中,其实就是指显存,不过严格来说,显存只是 global memory 的一部分。
gmem_readbw 顾名思义,就是测试显卡内存的读取带宽,从测试来看,W9100 的实测值是 289GiB/s,相对于理论值 320GiB/s 大约少 10%,这部份差别是正常的。gmem_readbw_strided:跨步式全局内存读取带宽。
这里增加了一个 strided 的后缀,表示存取不是完全连续的,读取的内存地址之间是存在间隔的,这样的存取方式显然会造成效率上要低不少。相对于 wx000 而言,wx100 跑这个测试的性能衰减情况要好一些,例如 W9100 的性能是连续读取的 27%,而 W9000 则下跌到 21%。基于 GCN 1.2 的 W7100 表现情况还更好一些,是连续读取时的 45%,而它的上一代 W7000 则下跌到 20%。gmem_writebw:全局内存写入带宽。
在连续写入测试中,蓝宝 PGS FirePro W7100 再次展现了较好的写入,达到了读取时 94% 的水平。 gmem_writebw_strided:跨步式全局内存写入带宽。
在跨步式写入测试中,所有测试卡都跌到了 8GiB/s 以下的水平。这个测试目前能跑出比较好成绩的还是得看 CPU。 lmem_readbw:局部内存读取带宽。
lmem 是指 OpenCL 中的 local memory,相当于 CUDA 中的 shared memory (早期 NVIDIA 曾经将其称作 PDC),AMD 则称之为 local data share 简称 LDS。local memory 是可以让 compute unit 中的 work-group 的各个 work-item 实现数据共享的存储层次,很大程度上可以看作是GPU 实现“高效”通用计算的关键所在。local memory 的“速度”一般都非常快,NVIDIA 曾经在 G80 的文件中提到 shared memory 的速度和寄存器一样快,请注意,我们这里说的速度其实是指时延。
目前的 GCN 中每个 compute unit 有 32KiB 大小的 local memory,每次的读写大小是 32 个 32-bit bank(存储体),这意味着 GCN 的每个 compute unit 的每次 local memory 存取可以获得 128 字节的低时延带宽。理论上,这个测试的测试值应该和 compute unit 的数量挂钩,不过从实际测试看,W9100 vs W7100 的数据比值(3.5 倍)还是要高于其 compute unit 比值(1.6 倍)。lmem_writebw:局部内存写入带宽。
这是测试local memory 写入带宽的测试,从测试结果看类似于读取带宽的结果,但是写入的性能要高于读取性能,可能是因为一些内部的合并写入优化机制或者其它原因。tex_readbw:纹理读取带宽。
tex在这里是指纹理,tex_readbw 自然是指纹理读取带宽测试。 在这里比较有趣的是 FirePro W5000 的性能要比想象中的快不少(甚至比理论值更快一些)。
level 1 包含了以下测试:
广度优先搜索(BFS):BFS 是一种对树进行完全遍历的搜索算法,在 SHOC 中的 BFS 测试采用了两种实现,分别来自斯坦福大学和伊利诺伊大学香槟分校(UIUC),SHOC 对这些算法进行了一些修改,使其可以适用满足正确性和多平台兼容性要求。测试的精度没有特别要求,因为“图(或者说关系树)”数据是无符号整型。
BFS 的四种求解规模分别是 1,000、10,000、100,000、1,000,000,我们测试的最高 100,0000 个图极点(Graph vertices)。这三个测试的前两个值的单位均为 GiB/s,意思是用带宽来表示性能,而第三个则是 Edges/s(这是“图”算法里常见的性能单位)。
测试结果表明 W9100 在运行 SHOC 的 BFS 可以达到每秒 153M Edges,由于这个测试是无符号整数,所以这里其实可以看作是整数相关的性能测试。快速傅里叶转换(FFT):测量单精度和双精度快速傅里叶转换的性能。
傅里叶变换是数字信号处理最常使用到的技术,例如把一堆信号里的高低频信号分离出来,就是傅立叶变换应用的拿手好戏,可以说没有傅里叶变换的话,整个信息产业可能都没法构建出来。SHOC 的 fft (快速傅里叶变换)测试值单位都是 GFLOPS/s,图表中的 ifft 是指快速傅里叶逆变换。
SHOC 提供了四个级别的 fft 求解规模,分别是 1、8、、96、256(单位是 MiB),我们设置为第四级即 256 MiB。 这个测试出来的性能比较容易受到驱动和 SDK 版本影响,不过因为我们都是使用同样的驱动和 SDK,所以测试出来的结果都比较合乎预期的样子。
如果数据是透过 PCIE 传输的话,对测试结果会有明显的影响。分子动力学(Molecular Dynamics,MD):测量进行分子动力学中的兰纳-琼斯势性能,该测试采用了在像 LAMMPS 应用中成品级 MD 代码所使用的 neighbor-list 算法。数据类型有单精度和双精度。
在 SHOC 中,MD 项目有四种求解规模:12288、24576、36864、73728,代表了求解对象的原子规模数,我们在这里采用了最高的 73728 个原子求解规模。在这个测试中,各个子项目均有两个测试值,例如 md_sp_flops 和 md_sp_bw,分别表示以单精度执行 md 求解的浮点操作数性能和带宽性能,单位自然分别是 GFLOPS 和 GiB/s。
也许是因为属于计算密集型测试的缘故,PCIE 的影响在这里相对小一些。 MD5Hash:SHOC 目前并未给出这个测试项目的细节,但是顾名思义,这是测试 MD5 哈希性能的项目。
MD5 目前在很多场合都有使用,例如文件下载,往往文件的提供者会有 md5 或者其它固定长度的字符串给下载者,用作检验文件的完整性。从测试来看,考虑到其功耗、单槽设计等特点,W7100 的表现不错,在这方面可以说是有较高竞争力的产品。归约(Reduction):用于测量大规模浮点加运算规约的性能。
归约测试分为本地和 PCIE 两种模式,测试结果单位是 GiB/s,NVIDIA 的 CUDA 手册中将这种计算作为按照 GPU 计算思想而逐步优化的经典范例。SHOC 给出的四种归约求解规模是以向量大小为单位的,分别是 1、8、32、64,单位是 MiB。
这里出现了双精度浮点测试比单精度更快的情况,原因之一就是双精度计算的存取数据要比单精度更高。并行前缀求和(Scan):测量对大规模浮点矩阵执行并行前缀求和的性能。
scan 就是给定一个数列,然后计算出另一个数列出来。例如: 有一个给定的数列: [3, 1, 7, 0, 4, 1, 6, 3]经过前缀求和后,就会得出另一个类似下面这样的数列:[3, 4, 11, 11, 15, 16, 22, 25] 这个例子的规律并不难看出,相信你稍微心算一下就明了了。
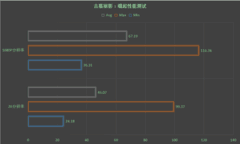
scan 的应用非常多,例如树操作、Quicksort、直方图等等。SHOC 提供的四个求解规模分别是 1、8、32、64 MiB,我们采用的是最高的64MiB,测试结果单位均为GiB/s,类似于前面的归约测试。蓝宝 PGS AMD FirePro W9100 的测试结果是38GiB/s 略低于蓝宝 PGS AMD FirePro W9000 的 42 GiB/s,这很可能是因为代码未充分优化导致的。
广义矩阵乘法(GEMM):测量 GEMM BLAS 性能,单精度。
GEMM 是高性能计算中最常使用的功能,所有的数学库都有该计算模块,像 Top500 的 HPL 就是典型的 GEMM 应用之一。SHOC 提供了 4 种预设的求解规模(单位 KiB):1、4、8、16,此外还可以用 -KiB 开关来指定求解规模,我们在这里使用预设的最高规模 16KiB。SGEMM 表示单精度、DGEMM 表示双精度、transpose 表示进行矩阵转置。
在SGEMM 测试中,蓝宝 PGS AMD FirePro W9100 的测试结果有些偏低,相比较之下,蓝宝 PGS AMD FirePro W7100 的矩阵转置性能相对较高。排序(Sort):测量无符号数矩阵基数排序性能。
sort(排序)算法有很多种,现在比较常用的是 quicksort,一般刚刚学编程的人士大都会以最简单、但并非最低效的冒泡算法来练手。排序的重要性是毋庸置疑的,例如要剔除重复项目的话,先对数据进行排序往往是必要的。SHOC 采用的排序算法是基数排序(redix sort),有四种求解规模,分别是 1、8、48、96,单位是 MiB,我们选择的是规模最大的 96MiB。
测试结果或者说排序率的单位是 GiB/s,用来表示执行排序 kernel 消耗的带宽。 从测试结果来看,消耗的带宽相当低,都是 1 GiB/s 不到,测试结果应该说是偏低的。
稀疏矩阵向量乘(SPMV):测量多种算法和数据结构下的稀疏矩阵向量乘法性能。
SHOC 的 SpMV 测试允许采用随机生成的矩阵或者指定一个矩阵文件,内建的随机矩阵规模有四种,分别是 1024、8192、12288、16384,我们测试的规模是第四个即 16384,正方形,默认的稀疏度为 1%。测试的 kernel 有三种存储格式,头两种都是基于 compressed sparse row (CSR,已压缩稀疏行) 数据结构,分别是 CSR-Scalar 和 CSR-Vector;第三种则是新近出现的 ELLPACKR 数据结构,所有测试结果都是 GFLOPS。
蓝宝 PGS AMD FirePro W9100 的 CSR-Scalar、CSR-Vector、ELLPACKR 单精度测试结果分别是 2.0、23.02、11.81(GFLOPS),符合预期。
Stencil2d:测量对一个二维 9 点单精度 stencil执行计算的性能(包括 PCIe 传输)。
Stencil2D 在早期的 SHOC 版本中是以秒为测试结果单位的,不过在新版本中已经改用 GFLOPS 作为测试结果。在 SHOC 提供的资料中,没有明确说明 Stencil2D 的求解规模,只是写着待定,我们在测试的时候所有都是指定为 -s 4,所以我假定这里的求解规模是最高的。
从测试结果来看,双精度时候的性能基本上是单精度的一半,估计代码尚有一定的优化空间,但是既然都是跑同样的代码,目前的测试结果也是有一定参考价值的。Triad:就是Stream 中Triad的OpenCL 版本,所谓的 Triad 就是把 Copy、Scale、Add 三种操作组合起来进行测试,在这里采用的是单精度执行计算。
Triad 的测试规模不受 -s 参数影响,测试的规模从 64KiB 到 16MiB,测试的结果是一个大规模向量点积操作的带宽,默认的测试结果单位是 GiB/s,涉及到 PCIE 总线传输,因此该测试对 GPU 来说瓶颈是在 PCIE 总线上。既然是卡在 PCIE 总线上,那么出现测试结果都是 6.x GiB/s 也就不奇怪了。
S3D:在一个标准三维栅格上测量遄流燃烧求解器计算的性能,这是一个浮点计算密集型的应用测试,栅格中每个栅格点的计算需要执行 10000 次浮点操作,这些栅格点都对应到 OpenCL 设备中一个的 work-item。
S3D 的测试规模按照单精度分别是 24、32、40、48,按照双精度分别是 16、24、32、40,我们测试选择的规模都是最高的第四级,即 48 和 40。S3D 的测试结果并不十分稳定,例如蓝宝 PGS AMD FirePro 录到的测试结果有 9x GFLOPS、也有 1x GFLOPS,我们在这里取的是其最高值。
如果打开系统监控器或者其它监控工具来观察的话,可以看到测试运行期间总有一个 CPU 内核在 100% 满载运行,使用 AMD 内建的工具查看,会发现很多时候 GPU 都没有满载、GPU 没有运行于最高的状态。CPU 满载的情况也许可以用测试的时候需要 CPU 孵化出大量数据给 GPU 运行来解释,而 GPU 未能满足的原因可能是因为 S3D 测试的规模相对于 GPU 来说有点喂不饱或者程序代码、OpenCL ICD 优化问题。
SHOC 是目前为数不多可以让大家比较容易获取、运行的超算类测试工具,它的特点是支持 OpenCL、CUDA 以及 OpenACC 以及 MPI 等异构并行方式的测试,测试的项目相对比较繁多,比较好地涵盖了大多数异构计算涉及的算法和内核,而且是开源项目,测试人员比较容易了解测试代码,可以根据实际情况进行调整。
我们这次进行的测试,是目前为止比较正规的 SHOC 测试,测试的对象是蓝宝 PGS 旗下的 AMD FirePro W 产品线,这个产品线采用的是 GCN 微架构,更贴合 OpenCL 的规格,由于时间关系以及专业卡驱动发布相对严谨,这次我们使用的驱动是去年年末的驱动版本。
从测试结果来看,所有的 SHOC OpenCL 项目都能在蓝宝 PGS AMD FirePro W 系列上正常运行,由于代码或者驱动优化的因素,在level 2 S3D 出现高端卡系列测试结果有波动的状况,这和卡或者说硬件本身没有什么关系,如果你也使用 SHOC 测试的话,应该对此加以注意。
Level 0 的测试结果要比 level 1 和 level 2 而言更平稳,不会出现忽大忽小的现象,因此这部份的测试结果是更可信的。
level 1 偶尔出现个别项目的波动,不过这样的情况不多见,建议测试人员应该至少跑三遍,确定波动不超过 10% 的情况下取最高值。
相对于大家常见的测试工具而言,SHOC 需要测试人员对算法、数据结构有一定的初步认识,除此以外,也要对 Linux 敲命令有心理准备(其实只要你能把 CentOS 塞进电脑,剩下的步骤基本上都在本文中能找到)。
以上是关于蓝宝石FireProW9100产品评测的报道,欢迎用户在文章下发表个人看法或@作者直接提问。有关蓝宝石FireProW9100产品的图赏、应用解析及视频等后续内容,敬请关注中关村在线关于蓝宝石FireProW9100评测的报道。
































评论
更多评论