字符串是一种常见的数据类型,在编程中应用广泛。掌握字符串的编码知识十分必要,它直接影响内存使用和字符显示是否正常。常见的编码方式如ASCII和UTF-8,各有特点,理解其原理有助于避免乱码问题,提升程序的兼容性与稳定性。
1、 全球程序员使用多种语言,各国文字差异大,若无统一编码标准,极易产生乱码。为兼顾兼容性与内存效率,UTF-8成为主流选择,它支持多语言混合编码,避免冲突,同时节省存储空间,提升程序运行效率,因此被广泛应用于软件开发中。
2、 在计算机内存中,通常采用Unicode编码来处理字符。当数据需要存储到硬盘时,则会转换为UTF-8编码格式。浏览网页时,服务器会将动态生成的Unicode内容转为UTF-8再发送至浏览器。通过查看网页源码或设置,我们也能观察到当前页面所使用的编码方式。
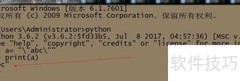
3、 要查询单个字符的编码,可使用Python内置的ord()函数。若想根据编码值反向查找对应的字符,则需使用chr()函数,两者功能互为逆操作。例如,查询字符A的编码时,将带单引号的A作为参数传入ord()函数,结果为65。同理,输入数字66调用chr()函数,即可得到其对应的字符。这两个函数在字符与ASCII编码之间转换时非常实用,操作简单且直观,适用于各类字符处理场景。
4、 从网络或硬盘读取数据时,获取的是字节流,需将其转换为字符串才能查看内容,这一过程需使用decode()函数。若字符串仅包含英文字符,可采用ASCII编码;但若包含中文字符,则无法使用ASCII编码,否则会引发错误。此时必须使用UTF-8编码方式,才能正确解析并显示中文内容,确保数据的完整性和可读性。
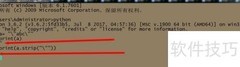
5、 若要查询字符串对应的编码,需使用encode()方法,调用格式为字符串.encode(编码格式),其中编码格式需用单引号括起,指定希望转换的编码类型即可完成编码转换操作。
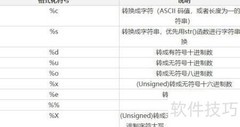
6、 在处理字符串时,还需掌握格式化输出的方法。其输出方式与C语言类似,通过%后接特定字母实现,如%d用于整数、%f用于浮点数、%s用于字符串。需注意百分号%本身的输出方法,以及整数符号的显示控制,还有浮点数中小数位数的设定规则,合理使用可提升输出结果的可读性与规范性。


































评论
更多评论