
【ZOL中关村在线原创评测】英特尔年初发布了首个基于Intel 18A制程工艺打造的Panther Lake处理器,在续航方面表现不俗,但如果论及性能的话,Panther Lake的顶级处理器依旧难以与锐龙平台相抗衡。尤其是在CPU多核性能、GPU图形性能等方面,AMD锐龙平台因为有锐龙AI Max+这一旗舰系列坐镇,因此依旧占据着性能高地。
而且在我们的测试中发现,今年AMD新推出的次旗舰锐龙AI Max+ 392就已经能够在性能上胜过Panther Lake顶级处理器酷睿Ultra X9 388H,更何况上面还有一个锐龙AI Max+ 395。不过二者之间的实际性能差异到底有多大?咱们一起来看看。
·测试平台简介
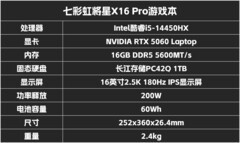
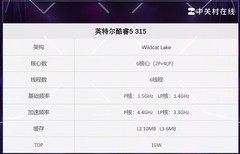
本次测试所使用的锐龙平台,我们选择了华硕天选Air2026锐龙AI Max版,它搭载了AMD锐龙AI Max+ 392处理器,32GB内存,1TB固态硬盘以及Radeon 8060S iGPU;与酷睿Ultra X9 388H机型相比,除了处理器不同之外,内存和硬盘容量都保持一致。同时在测试的时候我们使用了统一的Windows版本和最新的硬件驱动,以及各自平台最新的BIOS版本。
以下是两个处理器平台的基本信息。
这里需要注意的是,锐龙AI Max+ 392是12核24线程设计,酷睿Ultra X9 388H是16核16线程设计,因为不支持超线程;二者的最高加速频率只相差0.1GHz。而锐龙AI Max+ 392在缓存容量、内存位宽、最大内存容量支持方面占据绝对优势,酷睿Ultra X9 388H主要是在内存频率上略微超出。
·各项性能评估
接下来我们看看两颗当红处理器的性能表现到底存在怎样的差异?
【单核/多核理论性能】
CINEBENCH单核性能方面,英特尔酷睿一直以来是有优势的,尤其是在CINEBENCH R23和2024测试中,酷睿Ultra X9 388H分别得分2207和132,相对锐龙AI Max+ 392的1961分和111分领先11%和16%。但最新的2026版本测试中,也就是如果使用新版本C4D的话,锐龙AI Max+ 392的单核性能已经超过了酷睿Ultra X9 388H,领先幅度达到15%。
来到多核性能的比拼上,锐龙平台的优势就比较大了。CINEBENCH R23、2024、2026各版本多核得分27680、1378以及5773,分别领先酷睿Ultra X9 388H处理器26%、4%以及11%。所以综合来看,锐龙AI Max+ 392平台相对酷睿Ultra X9 388H平台是效率更高的选择。
单核和多核理论性能了解之后,咱们看看两颗处理器在常规应用中的表现。这里主要包含了压缩与解压缩速度、采样与渲染速度。
近年来AMD锐龙平台的每一代产品在压缩和解压缩速度上都明显领先英特尔酷睿平台,这主要是因为酷睿平台取消了超线程设计,从而拉低了压缩和解压缩这类主要依赖核心线程数量的应用的效率。
【压缩/解压缩速度】
7-ZIP压缩和解压缩速度方面,锐龙AI Max+ 392分别达到了117098KB/s和1886191 KB/s,分别领先酷睿Ultra X9 388H平台7%和62%,所以锐龙AI Max+ 392虽然核心数量上比酷睿Ultra X9 388H少4个,但毕竟全大核加24线程在压缩和解压缩上足以弥补核心数量差距,效率更高。
另外在7-ZIP基准测试总分上,锐龙AI Max+ 392也达到了151.607分,比竞品高出32%。
在7-ZIP测试之外,我们还引入了另一款老牌压缩/解压缩软件WinRAR,在两个平台的基准速度测试中,锐龙AI Max+ 392达到了25288KB/s,酷睿Ultra X9 388H为20977KB/s,锐龙平台领先21%。
其实压缩和解压缩这项应用不只是大家日常打包和解包文件这么简单,游戏、生产力办公等应用过程中,很多任务在执行之前都会在后台执行解压缩任务,此时虽然用户感知不到是处理器在做相应任务,但其效率的高低是确实存在差异的,所以选择压缩、解压缩速度更快的平台,在很多应用中都会潜移默化地获得更高的效率。
【采样与渲染性能】
采样与渲染,也是CPU在日常应用中最为常见的高负载任务。这方面其实早期的酷睿产品有着不小优势,但最近几年随着AMD推出锐龙AI Max系列产品,酷睿平台的优势已经荡然无存。
在V-Ray Benchmark 1分钟采样率测试中,锐龙AI Max+ 392的速度可以达到29286 vsamples,这个效率在移动端平台中是相当高的。对比酷睿Ultra X9 388H的22733 vsamples,领先幅度达到了29%。
Corona 10作为新版渲染插件有着极为广泛的应用,两个平台在Corona 10 Benchmark 1分钟光线渲染速度上也有着比较显著的差异。其中锐龙AI Max+ 392平台为9247838rays/s,而酷睿Ultra X9 388H仅为7093796rays/s,锐龙平台领先30%。
接下来是经典的Blender渲染器的测试,在Blender Benchmark 5.1 CPU采样率测试中,moster、junkshop、classroom三个场景的采样率测试中,锐龙AI Max+ 392平台分别领先酷睿Ultra X9 388H平台达30%、36%和49%,优势极其显著。
采样和渲染效率对于专业类用户而言非常重要,大型工程的渲染少则几个小时,多则数十个小时,如果效率不够高,那么所要付出的人力、能耗、时间成本就会非常高。所以相对效率明显更高的锐龙AI Max+ 392平台自然更适合承载这类重负载任务。
【GPU图形和游戏性能】
在酷睿Ultra X9 388H推出之后,其集成的锐炫B390核显因出色的图形性能而倍受好评,但其实这更多是相对此前Intel自己的核显而展现的性能水准来评判的。如果将锐炫B390核显放在锐龙AI Max+ 392集成的Radeon 8060S面前,在图形性能的比拼上就有明显劣势了。
如下图所示,3DMark Fire Strike、Time Spy、Steel Nomad Light三项测试中,Radeon 8060S图形性能远高于锐炫B390,分别领先67%、53%和72%。
在实际游戏测试中也可以看到,Radeon 8060S的原生游戏帧率普遍高于锐炫B390,不过从《黑神话:悟空》测试可以看到,锐炫B390在多帧生成加持下平均帧率高出Radeon 8060S平台5fps,但1% LOW方面却只有84fps,相对Radeon 8060S的126fps差了50%,如果画质开高,帧率压力上来的话,1% LOW更低的情况下,即便通过多帧生成拉高平均帧,实际游戏时画面还是会有明显的迟滞感,所以更高的1% LOW帧对于集成显卡而言其实更加重要一些。
整体来看,《黑神话》和《赛博朋克》两款游戏中两款显卡带来的平均帧仅有个位帧数差异很接近,但是最低帧或者关闭帧生成时Radeon 8060S明显胜出,最高领先50%,同样是3A经典的《极限竞速·地平线5》,Radeon 8060S更是大幅领先Arc B390核显帧数大约54%!如果是传统的电竞网游类游戏,相较于Arc B390核显,Radeon 8060S往往也有至少15%以上的帧数领先。
【综合性能】
综合性能方面,我们主要参考UL Procyon的照片编辑和视频编辑测试,这两项测试负载较高,对于硬件平台的压力也更大,能够更好地评估二者之间的差异。
可以看到,锐龙AI Max+ 392在照片编辑和视频编辑上分别得分6798和23917分,分别领先酷睿Ultra X9 388H平台3%和43%。这意味着在更吃GPU加速能力的视频编辑方面,锐龙AI Max+ 392的Radeon 8060S iGPU效率更加出色,如果你是做视频内容创作的话,锐龙AI Max+ 392平台整体体验会更高效。
在综合性能与离电性能方面,参考PCMark 10 Extended模式,锐龙AI Max+ 392分别得分12761和8574,而酷睿Ultra X9 388H平台分别为11439和7735,锐龙平台的领先幅度在12%左右。所以无论是固定插电使用,还是移动不插电使用,锐龙AI Max+ 392平台的体验都会更加流畅一些、效率会更高一些。
【AI大模型推理生成速度】
作为强调AI算力的移动端平台,锐龙AI Max+ 392和酷睿Ultra X9 388H在本地大模型推理生成上都能满足用户的基本需求。但如果论性能上限的话,锐龙AI Max+系列和酷睿Ultra是不在一个图层上的,毕竟如AI Max+392内存最高可以到128GB,通过统一内存架构和可变显存技术可以分配96GB给显存,本地运行70B大模型的能力,酷睿Ultra还是不能与之抗衡的。
不过本次对比测试为了公平,我们使用的锐龙AI Max+ 392搭配的是和酷睿Ultra X9 388H平台一样容量的32GB内存,此时AI大模型推理生成速度快慢,就要比拼GPU的硬实力了。可以看到,在Phi-3.5B、Mistral-7B、Llama-3.1-8B和Llama-2-13B测试中,锐龙AI Max+ 392推理生成速度平均领先幅度都超过了50%,最高的Llama-2-13B领先达到74%,所以论本地大模型能力,目前还是锐龙AI Max系列处理器更加强劲。
评测的最后一部分,我们来看看两个平台在内存性能以及功耗散热方面的表现。
【内存性能】
首先在内存读写与拷贝速度上,得益于统一内存架构的优势,锐龙AI Max+ 392的速度普遍更快,尤其是写入速度领先酷睿Ultra X9 388H达到61%。
不过内存延迟方面,这一代酷睿Ultra处理器在底层架构设计中加入了内存侧缓存,因此延迟只有87.6ns,这可以说是酷睿Ultra X9 388H相对锐龙AI Max+ 392为数不多的闪光点了。
【功耗与散热】
另外可能有朋友对我们测试平台是否处于同一功耗下存在疑问,毕竟抛开功耗去谈性能往往会造成误导。不过本次我们使用的测试平台功耗释放均设置为85W,另外在温度层面,锐龙AI Max+ 392为95.5℃,酷睿Ultra X9 388H为96℃,所以功耗释放和散热方面,两个测试平台是处于同一标准的。
·综合成绩汇总与评测总结
最后笔者把所有测试项目进行了汇总,另外两个平台在续航方面的表现也加入了表格之中。
通过UL Procyon 1小时Office办公和连续视频播放掉电测试可以看到,酷睿Ultra X9 388H平台在续航层面表现确实更加出色,1小时分别掉电2%和3%。而锐龙AI Max+ 392平台1小时分别掉电12%和14%,在能效方面,388H平台表现更好。
由于酷睿Ultra X9 388H有能效核心和低功耗能效核,续航表现更好。不过在性能和AI算力层面,锐龙AI Max+ 392对酷睿Ultra X9 388H几乎造成了全方位压制,无论是CPU侧的计算能力、尤其是多线程性能,还是GPU侧的图形、游戏,以及整体的AI性能,锐龙AI Max+ 392的总体表现都更加出色,整体优势非常显著。
所以,在选购时,还得要看具体的使用需求,如果需要更强悍的性能的话,很明显AMD锐龙AI Max+ 392平台是更好的选择。





























































































评论
更多评论