聚类是依据特定标准(如距离准则)将数据集划分为多个类或簇的过程,目标是使同一簇内的数据对象相似度尽可能高,而不同簇间的数据对象差异尽可能明显。换句话说,聚类旨在让同类数据紧密聚集,异类数据彼此远离,从而实现数据的有效分组与结构化分布。
1、 聚类分析的几个关键步骤
2、 对数据进行预处理,包括数量与类型选择、特征缩放及剔除异常值。
3、 定义距离函数以量化数据点之间的相似程度。
4、 将数据对象按特征划分为不同类别。
5、 评估聚类结果的准确性与有效性
6、 聚类无标签,分类有标签。
7、 聚类是一种无监督学习方法,旨在将相似的对象自动划分为不同组别。在聚类过程中,并不依赖已知的类别标签,也不关注每组具体代表什么含义,核心目标是将性质相近的数据归为一类。算法主要依据数据之间的相似程度进行分组,因此只需定义合适的相似性度量方式即可运行,无需预先训练模型或使用标注数据,完全依靠数据本身的特征结构实现自动聚合。
8、 分类旨在回答这是什么的问题,需预先告知类别信息。系统通过学习训练数据中的样本特征,掌握规律,进而对未知数据进行类别判断,这一过程依赖标注数据,属于监督学习范畴。
9、 聚类分析广泛应用于各个领域。
10、 用于识别不同客户群体,并通过消费行为分析其特征。
11、 对各地区城镇居民收入与消费情况的分类分析。
12、 识别社交网络中的用户群体结构。
13、 用于动植物及基因分类,揭示种群内在结构特征。
14、 通过聚类分析电子商务中浏览行为相似的客户群体,挖掘其共同特征,有助于企业深入理解用户需求,进而提供更加精准和个性化的服务,提升用户体验与满意度。
15、 识别已购汽车保险且平均赔付金额较高的客户群体。








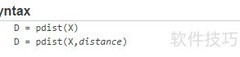




















评论
更多评论