正则表达式应用日益广泛,凭借其强大功能,可实现多种文本处理任务。例如,在句子中查找特定信息、过滤非法内容、提取网页数据、实现代码编辑器中的语法高亮等,均能通过正则表达式高效完成,极大提升了文本操作的灵活性与准确性。
1、 类似DOS中的通配符用法
2、 你是否还记得,在搜索文件时常用?和*这两个符号?它们就是DOS通配符,实际上也是最基础、最常见的正则表达式形式。这种模式匹配工具看似简单,却拥有强大的搜索功能,被广泛应用于各种文本处理场景之中。
3、 123.* 指文件名为123但扩展名不同的各类文件,例如123.txt、123.doc、123.wps、123.swf、123.xls等。
4、 中国?.doc指文件名为中国后接任意单个字符及.doc扩展名的文件,如中国1.doc、中国2.doc等。
5、 在DOS中,?表示任意单个字符,*表示任意多个字符,但在正则表达式中它们的含义有所不同。例如,*不再直接代表任意字符,而是有特定的匹配规则。接下来我们将了解正则表达式的具体规定。
6、 了解正则表达式基本规则
7、 正则表达式源于DOS通配符的扩展与深化,最常见的是用于文本匹配的各种符号组合。
8、 匹配其前面字符的零次或多次出现,如a*可匹配任意个a字符。
9、 .可匹配任意一个字符,如rat、rut、r t,但无法匹配root。
10、 相当于DOS中通配符的问号功能。
11、 ^ 表示字符串的起始位置。例如,^When 可以匹配 When in the course of human events 的开头,但无法匹配 What and When in the 这样的句子,因为该句并非以 When 开头。
12、 $$ 表示行尾位置。例如,正则表达式 weasel$$ 可以匹配Hes a weasel的结尾,但无法匹配They are a bunch of weasels.的末尾部分,因为该字符串中 weasel 后还有其他字符,不处于行尾位置。
13、 可用点号表示点,星号表示星号,此类情况较少见,若一时不解可先忽略,待实际应用时自然明了。
14、 正则表达式中有一强大符号,用括号括起的内容可实现无序匹配,灵活匹配不同顺序的字符组合。
15、 可匹配abc、acb、bac、bca、cab、cba六个字符串的任意一种排列组合。
16、 匹配0至9之间的任意单个数字
17、 匹配字符串中的全部小写英文字母
18、 查找并匹配全部大写英文字母
19、 可以将它们混合在一起,以这种方式书写。
20、 在文本检查中,若需排除数字,可使用^符号表示非或除了。
21、 匹配除数字外的所有文本内容
22、 匹配除字母外的所有字符内容
23、 筛选出不包含FONT字符的全部文本内容
24、 *
25、 前面元素可出现零次或多次
26、 .
27、 匹配任意一个字符
28、 ?
29、 前面元素可出现零次或一次
30、 +
31、 前面的元素至少出现一次
32、 ^
33、 开启全新篇章
34、 $$
35、 重新表述完毕。
36、 .*
37、 代表零个或多个任意字符。
38、 [ ]
39、 表示从a到z中任意一个字符的范围描述符。
40、 w
41、 英文字母与数字的组合形式。
42、 W
43、 非英文字符与数字
44、 s
45、 空字符,表示无内容的字符。
46、 S
47、 非空字符
48、 d
49、 数字,就是数值的表示。
50、 D
51、 非数值。
52、 词边界符在范围描述符外的字符
53、 B
54、 非词语分隔符
55、 退格符(0x08)在范围描述符内使用时
56、 元素出现次数在m到n次之间
57、 |
58、 选择
59、 ( )
60、 群组
61、 其他符号
62、 此字符自身
63、 基本规则已介绍完毕。接下来将讲解易语言中正则表达式的数据类型及相关命令,主要涉及两种类型:正则表达式和搜索结果,具体所示。
64、 首个正则表达式程序
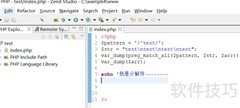
65、 创建易语言项目,界面布局参照示意图。
66、 按钮点击事件的代码如下所示
67、 定义局部变量:正则表达式1 和 正则表达式。
68、 创建正则表达式模式A.C,忽略大小写。
69、 将编辑框1的内容通过正则匹配后转为文本,再赋值给编辑框2。
70、 所示
71、 此处正则表达式1为一个正则对象,通过创建方法构建了A.C模式,随后将其与编辑框1中的内容进行匹配比对,最终得出匹配结果。
72、 运行程序后,输入以A开头、C结尾的三个字符均返回真,效果所示。
73、 若为小写或超过三个字符,返回结果为假,所示。
74、 有人可能会质疑这种匹配方式是否有实际意义。其实,其价值取决于具体应用场景。例如,在程序加密过程中,可利用正则表达式替代传统的判断或循环语句,用于验证注册状态、检查程序名称或内部文本内容。这种方式不仅简洁高效,还能增加逆向分析的难度,使不熟悉正则表达式的破解者难以轻易突破防护机制,从而提升软件安全性。
75、 第二个正则表达式示例
76、 通过第一个正则示例,读者将认识到正则匹配的关键作用,并掌握易语言正则支持库的基本用法。接下来的示例将进一步展示正则表达式能返回更多详细信息,以及如何有效提取这些内容。我们只需对前述程序的部分代码进行如下修改即可实现。
77、 定义局部变量:正则表达式1 和 正则表达式。
78、 局部变量在搜索结果中显示为0,表示未找到匹配项。
79、 创建正则表达式A.C,忽略大小写。
80、 在编辑框1的内容中,使用正则表达式进行全局搜索并匹配所有符合条件的结果。
81、 将搜索结果中与输入内容匹配的文本提取并显示在编辑框2中。
82、 中文重述,九字左右
83、 此处新增一个搜索结果对象,用于接收正则匹配内容,并从中提取所需数据。
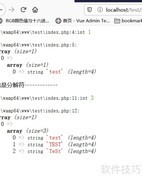
84、 易语言程序运行效果所示
85、 修改上方编辑框内容后,结果如下所示
86、 这是关键步骤之一,涉及获取A和C所包含的具体内容,以及后续将讨论的位置信息。这些被提取的内容具有重要意义,例如可准确获取括号内的信息,极大提升了查找效率与准确性,为后续分析提供有力支持。
87、 第三个示例程序
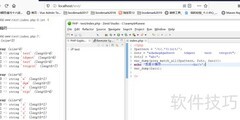
88、 本次任务是从一段文字中提取所有字母和数字字符。
89、 按钮单击事件的处理代码如下
90、 定义局部变量:正则表达式1 和 正则表达式。
91、 局部变量在搜索结果中显示为0,表示未找到匹配项。
92、 局部变量:数组索引,整数类型
93、 创建正则表达式,参数为字符串和布尔值假。
94、 中间的内容为待搜索的文本,可包含任意字符,如字母、数字、空格、换行符及各种特殊符号。需注意的是,若出现字符^,表示排除含义,例如^abc即代表除了abc。当前所给表达式的作用是匹配包含字母、数字和换行符的文本内容,末尾的假表示匹配时不区分大小写,写成真亦可,效果相同。
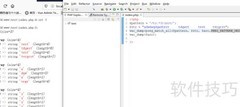
95、 在编辑框1中输入内容,使用正则表达式进行全局搜索匹配。
96、 搜索结果以数组形式存储,包含字符串匹配后的各项参数,如位置信息等。可通过取匹配文本(,)方法提取内容,需注意其首个参数应与搜索全部()所用参数保持一致。
97、 编辑框2的内容设置为空字符串。
98、 循环遍历搜索结果1的每个成员,索引从1开始直至数组长度。
99、 在编辑框2中输入文本,并从编辑框1的内容中查找匹配的文本结果。
100、 循环计数结束
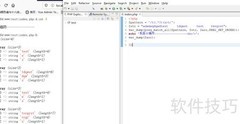
101、 所示
102、 程序运行后,用户可在编辑框输入中文及字母数字组合,点击按钮即可提取其中的字母和数字,具体效果所示。
103、 小型正则表达式工具
104、 大家将学习制作简易正则表达式工具,为后续章节的深入学习打下基础。
105、 程序界面布局如下所示
106、 按钮点击事件的代码如下所示
107、 定义局部变量:正则表达式1 和 正则表达式。
108、 局部变量在搜索结果中显示为0,表示未找到相关数据。
109、 局部变量 位置1,数据类型为整数
110、 根据组合框1的内容创建正则表达式,不区分大小写。
111、 若正则表达式1为空,则条件成立。
112、 将编辑框A至D及编辑框2的内容依次赋值为空字符串。
113、 返回主界面
114、 若真走到尽头
115、 将编辑框1的内容通过正则匹配后转为文本,填入编辑框2。
116、 在编辑框1中输入内容,使用正则表达式进行全局搜索匹配。
117、 若数组下标在搜索结果中为零,则条件成立。
118、 将编辑框A至D及编辑框2的内容依次赋值为空字符串。
119、 返回初始状态
120、 若真走到尽头
121、 将编辑框A的内容设置为在编辑框1内容中从位置1开始匹配到的搜索结果1中的文本。
122、 将位置1的内容转换为文本并填入编辑框B。
123、 将位置1与编辑框A内容长度相加后转换为文本,赋值给编辑框C的内容。
124、 将编辑框A内容的长度转换为文本,赋值给编辑框D的内容。
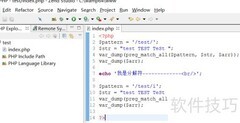
125、 运行上述代码后,效果如下所示。
126、 以上为测试匹配方法中的注释内容。
127、 匹配易语言4.0及其可选的模块或支持库后缀。
128、 检测易语言4.0支持库是否匹配正则表达式,并返回结果。
































评论
更多评论