深入解析Java中equals与hashCode方法的原理及应用。
1、 equals() 方法用于比较两个对象或变量的实际内容是否相等,无论是引用类型的对象内容,还是值类型的数据值。
2、 hashCode() 方法用于计算对象实例的哈希码,也称散列值。在 Object 类中,该方法基于对象的内存地址进行计算,因此每个对象的哈希码通常具有唯一性。然而,当某个类重写了 hashCode() 方法后,哈希码的生成规则将不再依赖内存地址,而是遵循新定义的逻辑,可能导致不同对象产生相同或不同的哈希值,具体结果取决于重写方式。
3、 在Java中引入hashCode方法,主要是为了提升大量对象比较时的效率。相较于equals方法,hashCode计算速度更快,因此被广泛应用于诸多集合类中,例如HashTable等数据结构。通常情况下,若两个对象通过equals方法判断相等,则它们的hashCode值必定相同,这是重写这两个方法时必须遵守的基本约定。然而,反过来并不一定成立:即使两个对象的hashCode值相同,它们的equals方法返回结果也可能为false,这是因为哈希冲突的存在,尽管发生的概率较小。基于这一特性,在集合中判断两个对象是否相等时,通常采用分步策略:首先比较两者的hashCode,若不相等则直接判定对象不相等;若hashCode相等,则进一步调用equals方法进行精确比对。只有当equals方法也返回true时,才最终认定这两个对象完全相等。这种机制在保证准确性的同时,有效提升了比较操作的整体性能。
4、 在Java编程语言中,equals()和hashCode()方法均继承自Object类,是所有类默认具备的基础方法。其中,equals()方法原本用于比较两个对象的内存地址,判断它们是否指向同一个实例,也就是比较引用的一致性。而hashCode()则是一个本地方法,其具体实现依赖于运行时所在的底层平台和虚拟机机制,通常会根据对象的内存地址或其他内部状态生成一个整型的哈希值。
5、 对于equals()方法,Java规范设定了若干必须严格遵守的通用约定,以确保对象比较的逻辑一致性。第一,对称性要求:若对象x与y相等,则y与x也必须相等。第二,自反性规定:任何对象与自身比较都应返回true。第三,传递性意味着:若x等于y,且y等于z,则x也应等于z。第四,一致性指出:只要参与比较的对象内容未发生变化,无论调用多少次equals()方法,结果都应保持一致。此外,还有两条明确限制:任何对象与null进行比较时,结果必须为false;与类型不同的对象比较时,也应返回false。
6、 关于equals()与hashCode()之间的关系,存在一定的关联规则。如果两个对象通过equals()判定为相等,那么它们的hashCode()返回值必定相同。反之,若两个对象的hashCode()不相等,则可以断定它们一定不相等。然而,当两个对象的hashCode()相等时,并不能确定它们一定相等,因为哈希值相同可能只是哈希碰撞的结果,此时仍需依赖equals()方法进一步判断实际内容是否一致。因此,在重写equals()方法的同时,通常也应重写hashCode(),以保证这两个方法在语义上保持协调。
7、 每当使用new创建一个Object对象时,JVM会将其存入一个哈希表中。这个过程基于对象的hashCode值进行定位。当后续需要比较对象或获取该对象时,JVM会先计算其hashCode,再通过该值在哈希表中快速查找对应对象。这种方式避免了逐个遍历的低效操作,显著提升了查找和比较的效率。整个机制依赖于hashCode的唯一性和散列算法的合理性,从而确保对象存储与检索的高效性。
8、 当使用new Object()创建对象时,JVM会根据该对象的HashCode值将其存入相应的哈希表中对应的位置。若多个不同对象计算出的HashCode值相同,即发生哈希冲突,系统会将这些具有相同哈希值的对象存储在同一个键对应的链表中。具体来说,在该哈希键位置形成一个单向链表,所有哈希码相同的对象依次添加到链表中,通过链式结构连接在一起,以此解决冲突问题,保障数据的正确存储与查找。
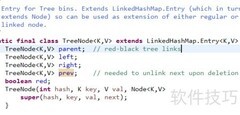
9、 比较两个对象时,首先查看它们的哈希码,并在哈希表中查找对应位置。若两个对象的哈希码相同,说明它们被存放在哈希表中同一键值对应的桶内,可能处于该桶所维护的链表或红黑树中,此时需进一步调用 equals 方法判断两者是否真正相等。只有当 equals 返回 true 时,才认为这两个对象内容一致。反之,若两个对象的哈希码不同,则它们必然不属于同一个存储位置,因此可以直接判定这两个对象不相等。哈希码的这一特性为对象比较提供了高效的前提筛选机制。
10、 上面的理论可能让人感到困惑,我自己看完也是一知半解。接下来,我将通过一个具体例子进行详细解释,帮助大家更好地理解。
11、 List允许重复元素,而Set不允许。当向Set中添加数据时,会先通过hashCode()方法判断哈希值是否已存在,若存在再调用equals()方法确认对象是否相等,以此确保元素的唯一性。
12、 若使用equals()方法,每存储一个新元素都需与集合中所有已有元素逐一比较。例如,当集合中已有100个元素时,插入第101个元素就需要执行100次equals方法调用,效率较低。
13、 若使用hashcode()方法,则通过哈希算法对数据进行存储和定位,提升存取效率。
14、 每次存储数据时,都会先调用hashcode()方法获取对应的哈希值,并确定存储位置。若该位置为空,则直接存入数据;若已有数据存在,则再调用equals()方法进行比较,若不相等则允许存储,相等则忽略。由于大多数情况下通过哈希值即可定位并避免冲突,equals()方法的调用次数大幅减少。尽管hashcode()被频繁调用,但整体性能明显优于频繁进行对象比较的方式,从而显著提升了存储效率和操作速度。
15、 默认情况下,Object类的equals方法比较的是两个对象的引用是否指向同一内存地址,只有地址相同才返回相等。若需根据对象内部的实际值判断相等性,就必须重写equals方法,使其按照具体属性值进行比较,从而满足业务逻辑中的相等判断需求。
16、 提到此处,许多人或许心存疑惑。关于String对象的equals()方法与==运算符的区别,大家可能都曾感到困惑。实际上,equals()用于比较字符串内容是否相同,而==则用来判断两个对象是否指向同一内存地址。
17、 这么说的话,equals怎么可能是比较地址?
18、 这是因为JDK中的String、Math等封装类均对Object类的equals()方法进行了覆盖,使其比较逻辑更符合实际需求。
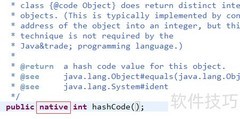
19、 先查看Object类中equals方法的源代码实现。
20、 所有对象都具备两个基本特征:标识和状态。其中,标识指的是对象在内存中的地址,而状态则代表对象所包含的数据内容。在Java中,==运算符用于比较两个对象的内存地址是否相同,因此它判断的是两个引用是否指向同一个实例。同样地,Object类提供的equals()方法默认也是基于内存地址进行比较的,也就是说,当object1.equals(object2)返回true时,意味着这两个引用实际上指向的是同一个对象。尽管这种比较方式在某些简单场景下可以满足需求,但在大多数实际应用中,我们更关心的是两个对象的内容是否一致,而非它们是否为同一实例。正因如此,许多封装类如String、Double、Integer以及Math等都对equals()方法进行了重写,使其不再比较内存地址,而是逐项对比对象内部的实际数据内容。这样一来,即使两个对象是分别创建的,只要它们包含的数据相同,equals()方法就能返回true。理解这一点非常重要,避免将==与的equals()方法混淆使用,从而确保逻辑判断的准确性。
21、 在程序运行期间,若对象用于equals比较的信息未发生变化,则多次调用其hashCode方法必须始终返回相同的整数值。
22、 若两个对象通过equals(Object o)方法判定相等,则它们各自的hashCode方法调用必须返回相同的整数值。
23、 若两个对象通过equals(Object o)方法判断为不相等,调用其中任意一个对象的hashCode方法并不要求返回不同的整数值。然而,若能尽量返回不同值,则有助于提升散列表的性能表现。
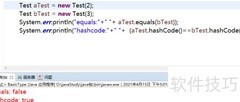
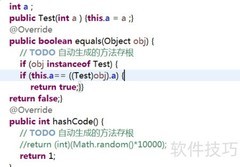
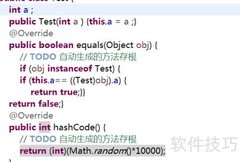
24、 根据前文分析,这一点很容易理解:若重写String的equals方法,使其基于内容比较而非内存地址,尽管两个对象内容相同、equals返回true,但它们的内存地址可能不同。而未重写hashcode时,仍默认依据内存地址生成哈希值,导致内容相同的对象哈希值不同,违反了equals为真则hashcode必须相等的约定,从而破坏了该方法应有的契约关系。
25、 例如,创建两个内容相同的对象,虽然它们的equals方法返回true,但若hashCode不同,在存入HashSet时会被视为两个不同的元素。因为HashSet首先根据hashCode进行查找,只有当hashCode相同时才会调用equals方法进一步判断,因此可能导致集合中出现逻辑上相等的重复对象。
26、 哈希表是一种基于数组实现的数据结构。由于依赖数组,其在创建后扩容较为困难,当数据量接近饱和时,性能会显著下降。此外,哈希表不支持按特定顺序遍历其中的元素,缺乏便捷的有序访问方式。然而,在不需要顺序访问且能预估数据规模的情况下,它具有极高的查找和插入效率,使用起来简单高效,因此在速度与实用性方面表现出极大优势,是许多场景下的理想选择。
27、 一个对象的哈希码(HashCode)本质上是某种简易哈希算法的具体实现。尽管这种实现相比复杂的真正哈希算法显得较为简单,甚至难以称为完整算法,但其设计质量直接影响对象在存储与检索过程中的性能表现。哈希码的设计不仅体现程序员的技术水平,更深刻影响着程序运行效率。在极端情况下,不同哈希策略可能导致对象存取性能相差数百乃至上千倍。以Java语言为例,HashMap和Hashtable是两个核心的数据结构。尽管二者在继承体系、是否允许空值以及线程安全等方面存在明显差异,但从底层原理来看,它们都依赖于哈希表机制来实现数据的快速定位与访问。因此,哈希码的合理生成对于这些结构的高效运作至关重要。若哈希分布不均或冲突频繁,将显著降低查找、插入和删除操作的速度,从而拖累整体系统性能。
28、 掌握这两项基本原则后,你便能够熟练地在程序中运用HashMap。值得注意的是,Java中Object类所提供的clone()、equals()和hashCode()这三个方法,虽然在设计上具有代表性,但其默认实现仅基于对象内存地址进行判断,在实际开发中往往无法满足需求。因此,我们需要根据具体业务逻辑,在自定义类中对这些方法进行重写。事实上,Java类库中的许多类也都重新实现了这些方法,以适应不同场景的需要。这种通过继承与多态机制实现的方法覆盖,不仅体现了面向对象编程的核心思想,也展现了Java作为一门纯面向对象语言的优雅与严谨。正是得益于这种灵活的设计,Java的集合框架才得以展现出强大的功能。Collection和Map等数据结构为程序提供了更加高效、灵活的存储与操作方式,显著提升了代码的可维护性与运行性能。深入理解HashMap的工作机制,有助于开发者编写出更高质量的程序。希望上述内容能帮助大家更有效地掌握和使用HashMap,提升编程实践能力。

























评论
更多评论