Saiku作为OLAP分析工具,首先需配置schema文件,随后添加数据源,将数据构建成立方体并存储于mv.db数据库中。用户在前端可通过选择维度、层级和度量等要素,以多维图表形式直观查看分析结果,实现灵活的数据透视与交互式探索。
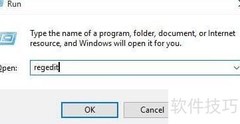
1、 添加schema文件时,需先根据数据关系编写相应文件。进入页面的DataSource Manage模块,选择Schema功能,点击add schema,输入schema名称后保存即可完成操作。整个过程简单直观,便于管理数据结构。
2、 添加完Schema后,接下来可配置数据源。进入管理控制台,依次选择数据源管理中的数据源选项,点击新增数据源。在弹出界面中,填写名称、连接类型、数据库地址、Schema名称、JDBC驱动类名及用户名等必要信息,确保各项参数准确无误后提交保存,即可完成数据源的添加操作。
3、 分析上述两个步骤的请求过程可知,前端页面通过发送REST请求,以application/json格式在请求体(request payload)中提交数据。后端服务由saiku-web项目中的AdminResource类负责接收处理,该类使用@Consumes({application/json})注解,确保仅接受JSON格式的数据。接收到请求后,系统自动将传入的JSON内容解析并映射为DataSourceMapper对象,完成数据转换与封装,从而实现前后端之间的结构化数据交互,保证了接口调用的规范性与数据的一致性。整个流程体现了典型的前后端分离架构设计。
4、 以添加数据源为例,详细描述HTTP请求的具体流程与参数传递方式。
5、 创建数据源的方法名称为createDatasource。
6、 请求地址为 http://localhost:8080/saiku/rest/saiku/admin/datasources,用于访问本地部署的 Saiku 服务中管理员数据源接口,实现相关数据操作与管理功能。
7、 请求方法为POST,用于提交数据。
8、 返回对象的类型被指定为org.saiku.web.rest.objects.DataSourceMapper,用于映射数据源相关信息,确保接口输出符合预定义的数据结构规范,便于前端解析与后续处理。
9、 请求内容类型为JSON格式,用于传输结构化数据。
10、 接收内容类型为 JSON 格式,通过 @Consumes 注解指定支持 application/json 的请求数据。
11、 响应内容类型设置为 JSON 格式,使用 @Produces 注解声明支持 application/json。
12、 结合下图表格进行分析。
13、 默认情况下,数据源采用Jackrabbit进行存储。addDatasource方法共有四种具体实现,可通过查看irm.saveDataSource接口了解,分别对应ClassPathRepositoryManager、JackRabbitRepositoryManager、MarkLogicRepositoryManager以及MockRepositoryManager。这四种管理器各自针对不同的存储环境和需求设计,支持从类路径读取、使用Jackrabbit内容仓库、接入MarkLogic数据库,或在测试环境中使用的模拟实现,从而提供灵活的数据源配置方案,满足多样化的系统集成要求。
14、 页面支持多维数据可视化展示。系统依据schema与数据源生成的cube,可在界面中灵活呈现。用户选择已配置的cube后,通过拖拽维度与指标字段即可生成对应数据视图。此外,还可将右侧图表组件拖入区域,实现多样化、更直观的图形化展示效果,提升数据分析的可读性与交互体验。




























评论
更多评论