
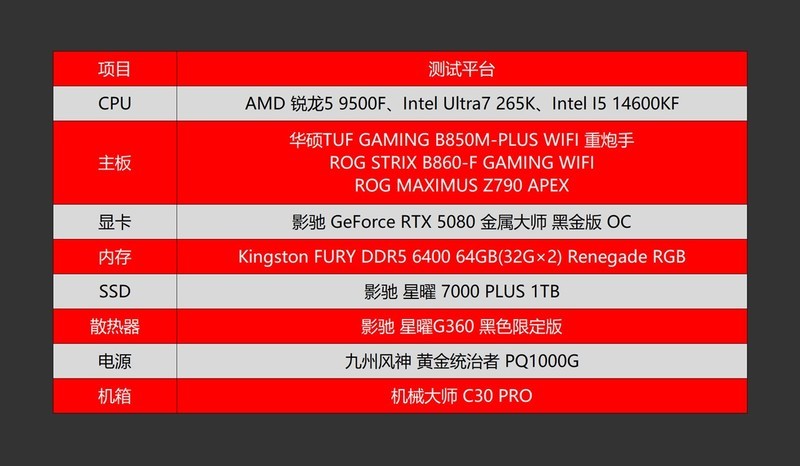
深夜实验室的终端仍在运行着第十七轮参数搜索,服务器队列排满,而手边那台旧工作站连加载BERT-base都开始卡顿——AI研究人员的日常,从来不是等待收敛,而是争分夺秒抢通算力瓶颈。当云资源受限、本地调试需低延迟响应、小规模模型迭代要求高频编译与快速I/O时,一颗兼具多线程吞吐、稳定超频潜力与合理功耗的CPU,远比盲目堆核数更贴近真实科研节奏。本次精选三款覆盖不同预算区间的成熟桌面级处理器,兼顾编译效率、虚拟环境隔离能力、多进程数据加载稳定性及长期运行可靠性,为高校课题组、独立研究者与AI工程化初探者提供扎实的本地算力基座。
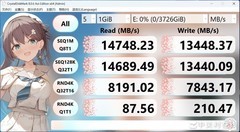
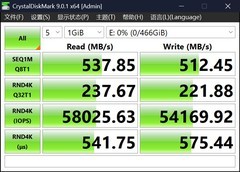
AMD Ryzen 9 3900X以2939.0元到手价位列首推。12核24线程设计,在TensorFlow分布式训练初始化、Conda环境批量构建及Docker镜像多层编译场景中展现出极强的并行韧性;Zen2架构带来的PCIe 4.0原生支持,显著缩短大型数据集从NVMe盘载入内存的等待时间;其未锁频特性配合B550主板可轻松达成稳定4.1GHz全核睿频,在不依赖高端散热的前提下完成持续3小时以上的模型验证任务,能效比优于同代多数竞品。
Intel 酷睿i9 10900K售价4210.0元,虽定位高端,但在需要单线程爆发力的场景中不可替代:如Python源码级调试、Cython模块编译、LLM tokenizer加载等对IPC敏感的操作,其单核睿频可达5.3GHz;搭配Z490平台可实现DDR4-2933高频内存直连,大幅优化NumPy矩阵运算内存带宽利用率;十核心二十线程结构在运行多实例Jupyter服务+后台日志采集+实时监控仪表盘时仍保持响应流畅,是小型AI实验室兼顾开发与轻量部署的理想中枢。
Intel 酷睿i5 10400F仅售880.0元,是学生研究者与开源项目维护者的务实之选。六核心十二线程已足够支撑ResNet-18训练、YOLOv5s量化部署及HuggingFace Transformers pipeline本地推理;无核显设计降低功耗与发热,特别适配长时间静音运行的文献复现实验环境;LGA1200接口主板生态成熟,升级路径清晰,未来可平滑过渡至11/12代酷睿,让有限预算真正服务于算法探索而非硬件焦虑。
三款产品横跨入门、进阶与主力工作站层级,价格梯度合理,架构特性互补,不堆砌参数而聚焦AI工作流中的真实卡点——从pip install的等待时长,到dataloader启动的IO抖动,再到多实验并行时的温度墙控制。选择它们,不是购买一颗芯片,而是为下一次loss曲线陡降,铺就更短的本地验证路径。










































































































评论
更多评论