
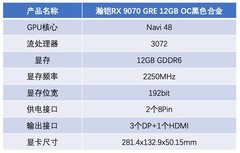
深夜实验室的终端仍在编译,CUDA任务队列持续滚动,Transformer层参数在16个物理核心间高速调度——对AI研究者与模型训练工程师而言,CPU早已不是‘辅助单元’,而是决定数据加载效率、特征工程速度、多卡通信协调能力与本地小规模训练迭代节奏的核心枢纽。当LoRA微调需频繁读写千兆级缓存、当Docker容器集群依赖高并发线程调度、当ONNX Runtime需最大化利用NUMA节点资源,一颗兼具高核心数、低延迟内存子系统、宽PCIe通道与稳定功耗墙的十六核处理器,就是生产力跃迁的第一块基石。
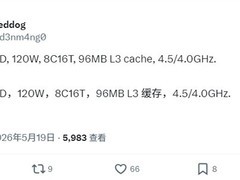
AMD Ryzen 9 7945HX以5nm Zen 4架构构建出当前移动工作站级的极致平衡:16核32线程全时可用,5.4GHz单核睿频保障编译与调试响应,64MB大容量L3缓存显著提升BERT类模型预处理中的token缓存命中率;其原生支持DDR5-5200双通道与PCIe 5.0×16通道,可直连两块高性能NVMe SSD构建高速数据集缓存池,同时为多GPU拓扑预留充足带宽。55W TDP设计兼顾散热可行性与持续多线程负载能力,在无外接显卡的轻量训练或强化学习仿真环境中,Radeon 610M核显亦可承担基础可视化任务,到手价为0元,实为高性价比入门AI开发平台首选。
Intel酷睿i9-7960X虽属上代旗舰,但其16核32线程全大核设计、22MB三级缓存及44条PCIe 3.0通道,在需要超长稳定性运行的模型蒸馏或遗传算法搜索任务中仍具不可替代性。其LGA 2066平台支持四通道DDR4内存,理论带宽达76.8GB/s,配合ECC内存(依主板而定)可大幅降低万亿级参数矩阵运算中的静默错误风险,适合部署于高校计算中心长期值守型训练节点,11899元售价对应的是经五年高强度验证的工业级可靠性。
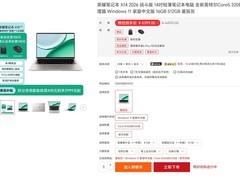
酷睿i9-12900K凭借创新的8P+8E混合架构,在AI流水线中展现独特优势:性能核专注编译、调试、单线程密集型算子调度,能效核后台持续处理日志聚合、监控上报与数据清洗,30MB智能共享缓存有效缓解跨核通信瓶颈;对TensorRT优化、OpenVINO部署及ONNX模型转换等典型边缘推理准备流程,其PCIe 5.0与DDR5双模支持带来显著加速,4430元价位精准锚定中小团队模型交付阶段的效能临界点。
i7-13700F则代表第十三代高能效演进方向:14核20线程(6P+8E)、24MB缓存、5.0GHz睿频,配合DDR5-5200与HDMI 2.1直出能力,在需要兼顾本地模型演示、实时数据仪表盘渲染与轻量训练的复合场景中游刃有余;其45W基础功耗与115W睿频功耗区间,适配紧凑型准系统与静音工作站,到手价为0元,是学生课题组与初创AI实验室构建最小可行开发环境的理想载体。
从实验室原型验证到产线模型迭代,十六核心已非奢侈配置,而是AI工程化落地的基础设施标配。四款处理器覆盖不同代际、功耗层级与扩展逻辑,共同指向一个清晰事实:在数据即燃料、时间即成本的AI时代,选择一颗真正懂并行、懂内存、懂IO协同的CPU,就是为每一次反向传播节省毫秒,为每一版模型上线缩短小时。






































































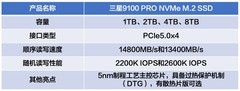






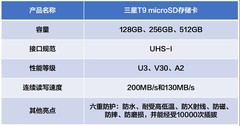



















评论
更多评论